苹果推出的视频识别模型:FastVLM,让AI有了眼睛
分类:AI资讯 浏览量:508
视觉语言模型 (VLM) 能够支持文本输入的同时进行视觉理解。它们通常是通过将视觉 token 从预训练的视觉编码器通过投影层传递到预训练的大型语言模型 (LLM) 来构建的。通过利用视觉编码器丰富的视觉表征以及 LLM 的世界知识和推理能力,VLM 可以广泛应用于各种应用,包括无障碍助手、UI 导航、机器人技术和游戏。
VLM 的准确度通常会随着输入图像分辨率的提高而提升,因此需要在准确度和效率之间做出权衡。对于许多生产用例而言,VLM 需要兼顾准确度和效率,以满足实时应用的低延迟需求,并在设备端运行以实现兼顾隐私保护的 AI 体验。
在一篇被 CVPR 2025 录用的论文中,Apple 机器学习研究人员最近分享了一种应对这一挑战的新技术:FastVLM。这是一种新型的视觉语言模型 (VLM),其设计简洁,显著改善了准确率与延迟之间的权衡。FastVLM 利用专为高分辨率图像设计的混合架构视觉编码器,提供准确、快速且高效的视觉查询处理,非常适合为设备上的实时应用程序提供支持。推理代码、模型检查点以及基于 MLX 的 iOS/macOS 演示应用可在此处获取。
图像分辨率与准确度-延迟权衡
通常,VLM 的准确率会随着图像分辨率的提高而提升,尤其是在需要详细理解的任务中,例如文档分析、UI 识别或回答关于图像的自然语言查询。例如,在下图 1 中,我们向 VLM 询问图像中可见的路牌。左侧,模型接收到低分辨率图像,无法正确响应。右侧,VLM 接收到高分辨率图像,并正确识别出“禁止驶入”的交通标志。

高分辨率显著增加了视觉语言模型 (VLM) 中第一个标记的时间 (Time-to-first-token)。使用高分辨率图像虽然可以提高准确率,但也会在两个方面降低效率:1) 更高分辨率的图像需要更长的时间用于视觉编码器的处理;2) 编码器会创建更多视觉标记,这会增加 LLM 的预填充时间。这两个因素都会增加第一个标记的时间 (TTFT),即视觉编码时间和 LLM 预填充时间的总和。如下图 2 所示,随着图像分辨率的提高,视觉编码时间和 LLM 预填充时间都会增加,而在高分辨率下,视觉编码器的延迟成为主要瓶颈。为了解决这个问题,我们的研究引入了 FastVLM,这是一种全新的视觉语言模型,可以在不牺牲准确率的情况下显著提高效率。
延迟细分
适用于 1.5B VLM (fp16)
视觉编码 LLM 预填
For an input image resolution of 256px: Vision Encoding latency is 6.8ms, and LLM Prefilling latency is 49.8msFor an input image resolution of 512px: Vision Encoding latency is 21.2ms, and LLM Prefilling latency is 70.7msFor an input image resolution of 768px: Vision Encoding latency is 54.8ms, and LLM Prefilling latency is 97.6msFor an input image resolution of 1024px: Vision Encoding latency is 116.4ms, and LLM Prefilling latency is 116.9msFor an input image resolution of 1536px: Vision Encoding latency is 883.7ms, and LLM Prefilling latency is 281.9ms02004006008001,000Latency (ms)25651276810241536Input Image Resolution (px)图 2:高分辨率下视觉延迟占主导地位。FastVLM 在不同图像分辨率下获取第一个 token 的时间细分。视觉编码器为 FastViT-HD,LLM 拥有 15 亿个参数。
混合视觉编码器实现最佳的精度-延迟平衡
为了确定哪种架构能够实现最佳的准确率-延迟权衡,我们系统地比较了现有的预训练视觉编码器,并进行了一项实验,其中所有内容(训练数据、配方、LLM 等)保持不变,仅更改了视觉编码器。在下方图 3 中,x 轴表示 TTFT,y 轴表示不同 VLM 任务的平均准确率。我们展示了两个基于 Transformer 的编码器 ViT-L/14 和 SigLIP-SO400 的点,它们在其原始分辨率下使用图文数据进行了预训练。我们还展示了 ConvNeXT (全卷积编码器)和 FastViT(结合了卷积和 Transformer 模块的混合编码器)在不同分辨率下的曲线。 FastViT 基于我们之前的两项工作( FastViT ,ICCV 2023;和 MobileCLIP ,CVPR 2024),与其他视觉编码器相比,实现了最佳的准确度-延迟权衡——比 ViT-L/14 小约 8 倍,快 20 倍。
与 FastViT 的性能比较
ViT-L/14SigLIP-SO400ConvNeXT-L 快速维生素
ViT-L/14
FastVit data points: Time to First Token (TTFT in ms) is 31.8; Ag-5 VLM Evals is 48. Time to First Token (TTFT in ms) is 63.1; Ag-5 VLM Evals is 52.1. Time to First Token (TTFT in ms) is 162.8; Ag-5 VLM Evals is 54.7. Time to First Token (TTFT in ms) is 320.3; Ag-5 VLM Evals is 56.ViT-L/14 data points: ViT-L/14: Time to First Token (TTFT in ms) is 255.7; Ag-5 VLM Evals is 47.3.02505007501000Time to First Token (TTFT in ms)4850525456Ag-5 VLM EvalsViT-L/14图 3:VLM 中不同视觉编码架构的比较。所有视觉编码器均使用 CLIP 进行预训练,并使用相同的设置(数据集、方案、LLM 大小)进行训练。FastViT 混合架构实现了最佳的准确率-延迟权衡。Avg-5 是该模型在 GQA 上的平均性能。 TextVQA 、 DocVQA 、 SeedBench 和 POPE 基准。
FastViTHD:适用于 VLM 的最佳视觉编码器
虽然 FastViT 混合主干是高效 VLM 的理想选择,但为了提高挑战性任务的准确性,需要更大的视觉编码器。最初,我们只是简单地增加了每个 FastViT 层的大小。然而,这种简单的缩放使得 FastViT 在更高分辨率下效率甚至低于全卷积编码器。为了解决这个问题,我们设计了一个全新的主干 FastViTHD,专门用于高分辨率图像。与 FastViT 相比,FastViTHD 增加了一个阶段,并使用 MobileCLIP 方案进行预训练,以生成更少但更高质量的视觉标记。
与 FastViT 相比,FastViTHD 在高分辨率图像上的延迟更低,但为了评估哪个在 VLM 中表现最佳,我们比较了它们与不同大小的 LLM 结合使用时的性能。我们评估了不同的(图像分辨率,LLM 大小)对,以及三个参数分别为 0.5B、1.5B 和 7B 的 LLM(分别对应下图 4 中的曲线),并将其与以不同分辨率运行的视觉主干网络配对。
如图 4 所示,使用非常高分辨率的图像和较小的 LLM 并不总是最佳选择;有时,最好将 LLM 切换到较大的 LLM,而不是提高分辨率。对于每种情况,我们都用虚线显示帕累托最优曲线,该曲线显示给定运行时间预算(此处为 TTFT)的最佳值(图像分辨率、LLM 大小)。与帕累托最优曲线相比,FastVLM(基于 FastViTHD)比基于 FastViT 的模型提供了更好的准确度-延迟权衡。在相同准确度下,它的速度可提高 3 倍。请注意,我们已经证明 FastViT 明显优于纯粹基于 Transformer 或基于卷积的编码器。
按模型大小划分的帕累托最优曲线
5亿 15亿7B 快速维生素
FastVitHD
FastVit data points: Time to First Token (TTFT in ms) is 31.8; Ag-5 VLM Evals is 47.7. Time to First Token (TTFT in ms) is 63.1; Ag-5 VLM Evals is 51.5. Time to First Token (TTFT in ms) is 162.8; Ag-5 VLM Evals is 54.4. Time to First Token (TTFT in ms) is 320.3; Ag-5 VLM Evals is 55.5. Time to First Token (TTFT in ms) is 2221.4; Ag-5 VLM Evals is 55.6.FastVitHD data points: Time to First Token (TTFT in ms) is 31.7; Ag-5 VLM Evals is 47.9. Time to First Token (TTFT in ms) is 50; Ag-5 VLM Evals is 52.5. Time to First Token (TTFT in ms) is 95.9; Ag-5 VLM Evals is 54.3. Time to First Token (TTFT in ms) is 166.9; Ag-5 VLM Evals is 55.2. Time to First Token (TTFT in ms) is 1012; Ag-5 VLM Evals is 55.9.10100100010000Time to First Token (TTFT in ms)455055606570Ag-5 VLM Evals图 4:FastViT 和 FastViT-HD 主干网络与不同大小和不同图像分辨率的 LLM 配对的比较。虚线表示两个视觉主干网络的帕累托最优曲线。注意,x 轴是对数刻度。Avg-5 是该模型在 GQA、TextVQA、DocVQA、SeedBench 和 POPE 基准测试中的平均性能。
FastVLM:基于 FastViTHD 的新型 VLM
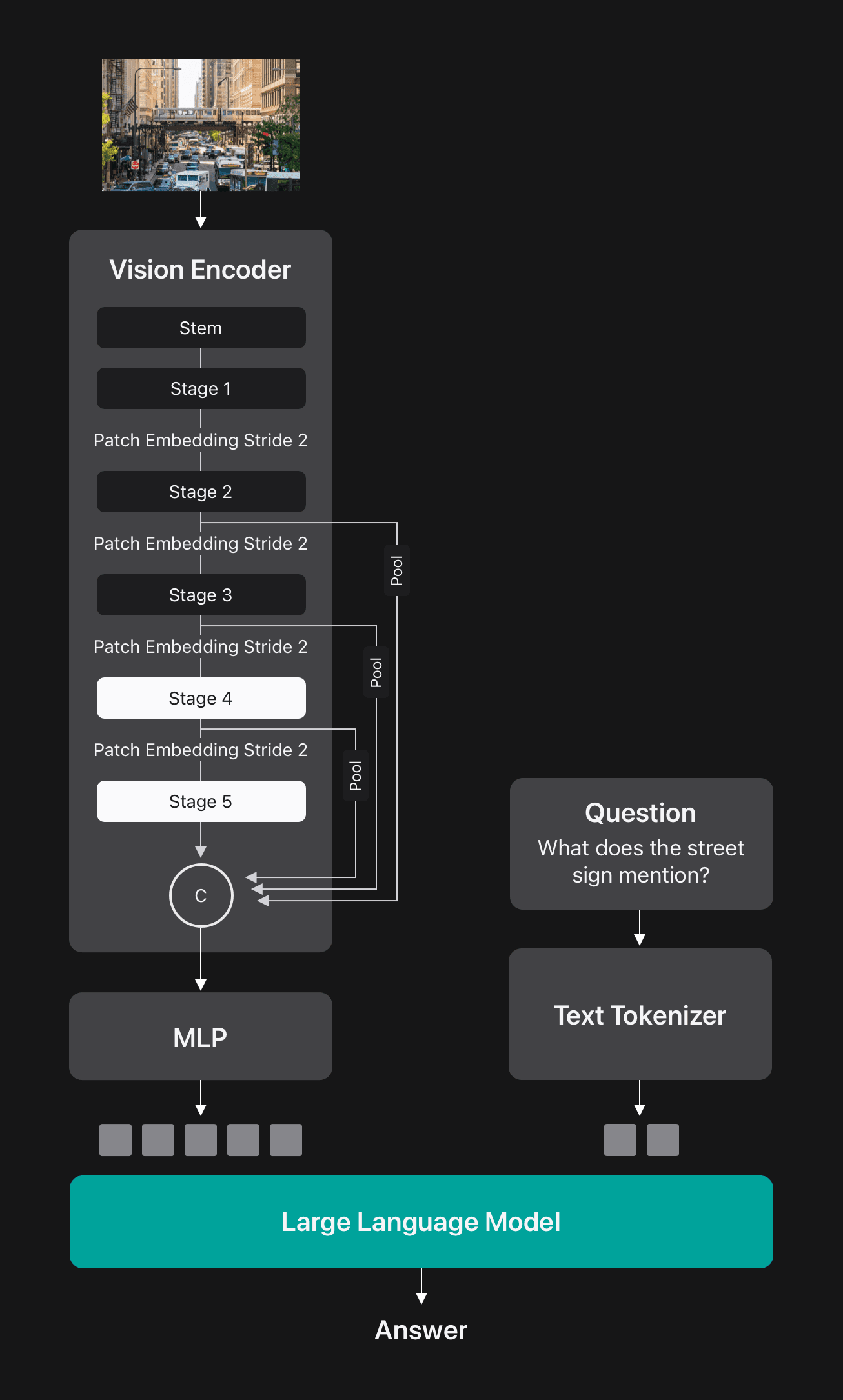
FastViTHD 是一种混合卷积-Transformer 架构,包含一个卷积主干、三个卷积级和两个后续的 Transformer 模块级。每个级之前都有一个块嵌入层,用于将输入张量的空间维度缩小一半。我们使用 FastViTHD 作为视觉编码器,构建了 FastVLM,并使用一个简单的多层感知器 (MLP) 模块将视觉 token 投影到 LLM 的嵌入空间, 如图 5 所示。
FastVLM 优于标记修剪和合并方法
先前在加速 VLM 方面的研究工作采用了复杂的合并或剪枝技术来减少视觉 token 数量,从而加快 LLM 的预填充速度(并进而缩短获取第一个 token 的时间)。如下图 6 所示,与这些方法相比,FastVLM 在不同视觉 token 数量(对应不同的输入分辨率)下实现了更高的整体准确率。这得益于其 FastViTHD 编码器提供的高质量视觉 token,并且由于 FastVLM 不需要复杂的 token 剪枝或合并,因此部署起来更加简单。
性能比较
FastVLM data points: FastVLM (16): Number of Visual Tokens is 16; Avg Performance is 68. FastVLM (64): Number of Visual Tokens is 64; Avg Performance is 71.1. FastVLM (144): Number of Visual Tokens is 144; Avg Performance is 71.9. FastVLM (256): Number of Visual Tokens is 256; Avg Performance is 72.4.FastV data points: FastV (64): Number of Visual Tokens is 64; Avg Performance is 49.6. FastV (192): Number of Visual Tokens is 192; Avg Performance is 60.9.SparseVLM data points: SparseVLM (64): Number of Visual Tokens is 64; Avg Performance is 62. SparseVLM (192): Number of Visual Tokens is 192; Avg Performance is 68.4.VisionZip data points: VisionZip (64): Number of Visual Tokens is 64; Avg Performance is 67.4. VisionZip (192): Number of Visual Tokens is 192; Avg Performance is 69.7.DynamicLLaVA data points: DynamicLLaVA (115): Number of Visual Tokens is 115; Avg Performance is 70.1.050100150200250300Number of Visual Tokens506070Avg PerformanceFastVLM (16)FastVLM (64)FastVLM (144)FastVLM (256)FastV (64)FastV (192)SparseVLM (64)SparseVLM (192)VisionZip (64)VisionZip (192)DynamicLLaVA (115)图 6:FastVLM 在不同输入图像分辨率、不同视觉 token 数量以及不同 token 剪枝和合并方法下的平均性能比较。纵轴表示模型在 GQA、TextVQA、ScienceQA、SeedBench 和 POPE 基准测试中的平均性能。
FastVLM 和动态平铺
如前所述,VLM 的准确率会随着输入分辨率的提高而提高,尤其是在需要理解精细细节的任务中。动态分块(例如,在 AnyRes 中)是处理超高分辨率图像的一种常用方法。这种方法将图像划分为更小的分块,通过视觉编码器分别处理每个分块,然后将所有 token 发送到 LLM,如下图 7 所示。
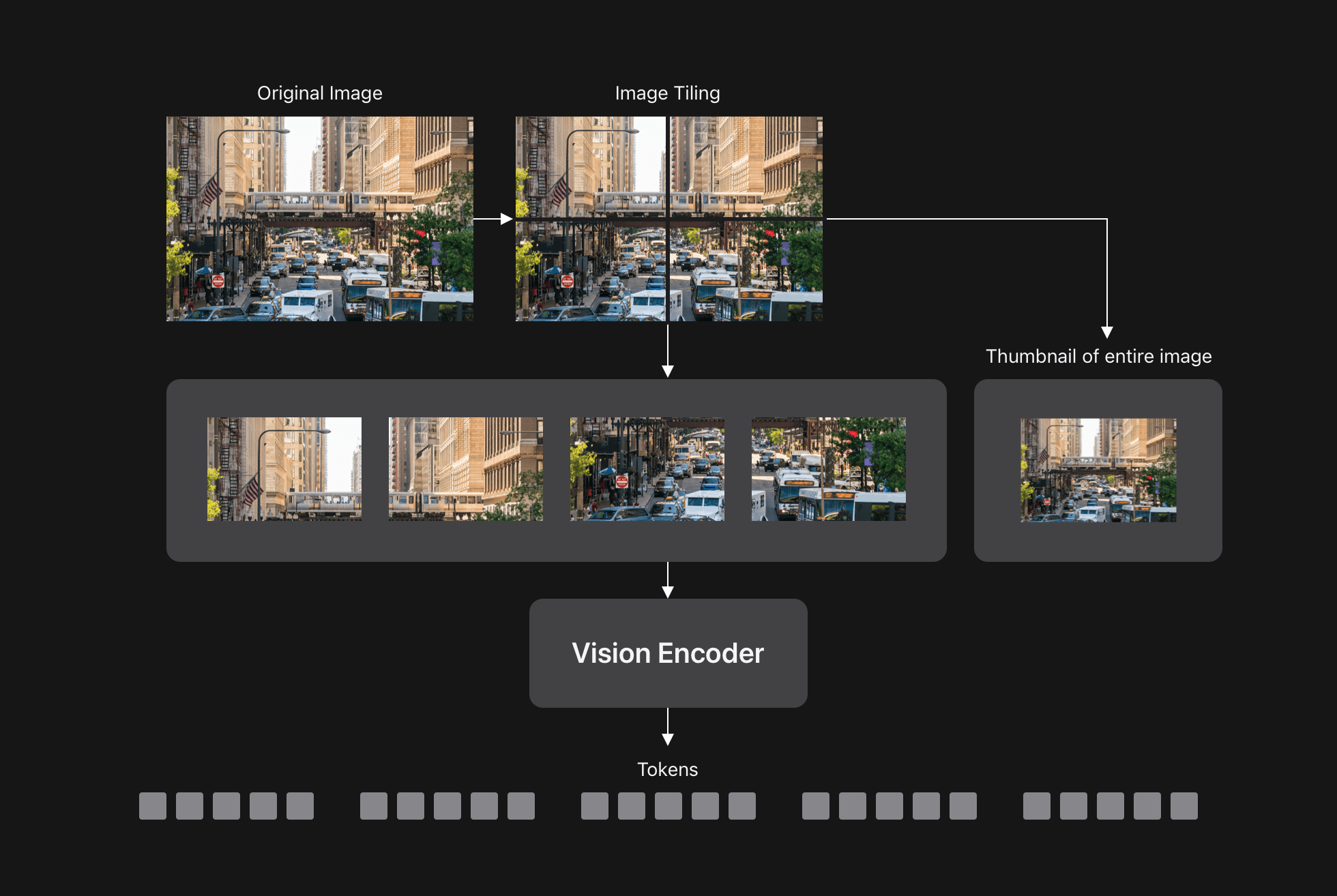
由于 FastVLM 天生擅长处理高分辨率图像,我们探索了将 FastVLM 与动态平铺相结合能否改善其准确率与延迟之间的平衡。下图 8 显示,不带平铺的 FastVLM(蓝色曲线)相比带动态平铺(粉色点)实现了更佳的准确率与延迟之间的平衡,即使在极高的图像分辨率下,将 FastVLM 与 AnyRes 结合使用也会带来益处。
平铺对性能的影响
2x23x34x4 无平铺 动态平铺(AnyRes)
No Tiling data points: Time to First Token (TTFT in ms) is 154.5; Ag-5 VLM Evals is 60.4. Time to First Token (TTFT in ms) is 387.4; Ag-5 VLM Evals is 62.8. Time to First Token (TTFT in ms) is 577.5; Ag-5 VLM Evals is 63.9. Time to First Token (TTFT in ms) is 2053.8; Ag-5 VLM Evals is 64.8.Dynamic Tiling (AnyRes) data points: Time to First Token (TTFT in ms) is 271.1; Ag-5 VLM Evals is 59.8. Time to First Token (TTFT in ms) is 419.6; Ag-5 VLM Evals is 62. Time to First Token (TTFT in ms) is 675.5; Ag-5 VLM Evals is 63.3. Time to First Token (TTFT in ms) is 1861.9; Ag-5 VLM Evals is 64.8.101000Time to First Token (TTFT in ms)606264Ag-5 VLM Evals图 8:FastVLM 的动态平铺 (AnyRes) 仅在最高分辨率和使用较少平铺 (2×2) 时达到最佳效果。平铺网格大小在括号中指定。注意,x 轴为对数刻度。Avg-5 是该模型在 GQA、TextVQA、DocVQA、SeedBench 和 POPE 基准测试中的平均性能。
FastVLM 比同等规模的主流 VLM 速度更快、更准确
最后,我们将 FastVLM 与其他流行的 VLM 进行了比较。下图 9 展示了 FastVLM 的两条曲线:一条使用了 AnyRes(以实现最高精度),另一条不使用 Tiling(以实现最佳精度-延迟权衡),每条曲线都使用了三种不同大小的 LLM 进行测试。FastVLM 的速度和精度都显著高于同大小的主流模型,如箭头所示:它比 LLava-OneVision (0.5 亿 LLM)快 85 倍,比 SmolVLM (~0.5 亿 LLM)快 5.2 倍,比 Cambrian-1 (7 亿 LLM)快 21 倍。
按模型大小进行性能比较
FastVLM data points: FastVLM (0.5B): Time to First Token (TTFT in ms) is 166; Avg-7 VLM Evals is 64.8. FastVLM (1.5B): Time to First Token (TTFT in ms) is 233; Avg-7 VLM Evals is 70.5. FastVLM (7B): Time to First Token (TTFT in ms) is 641; Avg-7 VLM Evals is 76.2.Cambrian-1 data points: Cambrian-1 (7B): Time to First Token (TTFT in ms) is 5085; Avg-7 VLM Evals is 68.8.LLaVA OneVision data points: LLaVA OneVision (0.5B): Time to First Token (TTFT in ms) is 14124; Avg-7 VLM Evals is 59.1.LLaVA-Next data points: LLaVA-Next (7B): Time to First Token (TTFT in ms) is 20347; Avg-7 VLM Evals is 63.1.SmolVLM data points: SmolVLM (0.5B): Time to First Token (TTFT in ms) is 868.7; Avg-7 VLM Evals is 64. SmolVLM (2B): Time to First Token (TTFT in ms) is 5618.8; Avg-7 VLM Evals is 70.9.100100010000100000Time to First Token (TTFT in ms)556065707580Avg-7 VLM EvalsFastVLM (0.5B)FastVLM (1.5B)FastVLM (7B)Cambrian-1 (7B)LLaVA OneVision (0.5B)LLaVA-Next (7B)SmolVLM (0.5B)SmolVLM (2B)图 9:FastVLM 与主流 VLM 的比较。箭头表示与类似大小的 VLM 的比较,突显了 FastVLM 卓越的准确率和显著更快的性能。Y 轴表示该模型在 ChartQA、TextVQA、DocVQA、OCRBench、AI2D、MMMU 和 ScienceQA 基准测试中的平均性能。
为了进一步展示 FastVLM 在设备上的效率,我们发布了一款基于 MLX 的 iOS/macOS 演示应用 。 图 10 展示了 FastVLM 在 iPhone GPU 上本地运行的示例。FastVLM 近乎实时的性能可以实现全新的设备端功能和体验。图 10:在 iPhone 16 Pro 上运行 FastVLM 0.5B 模型的演示应用。屏幕上显示了第一个令牌的时间,突出显示了近乎实时的性能。
结论
通过结合视觉和文本理解,VLM 可以为一系列实用应用提供支持。由于这些模型的准确率通常与输入图像的分辨率相对应,因此准确率和效率之间往往存在性能权衡,这限制了 VLM 对于同时需要高精度和高效率的应用的价值。
FastVLM 利用专为高分辨率图像构建的混合架构视觉编码器 FastViTHD 解决了这一问题。FastVLM 设计简洁,在准确性和效率方面均优于现有方法,从而实现了适用于实时设备端应用的设备端视觉查询处理。
来源:https://machinelearning.apple.com/research/fast-vision-language-models